
BioWire Bytes 015 — ChatGPT-5
Byte-sized Biotech


OpenAI finally shipped GPT-5, it’s first “numbered” model since GPT-4 in March 2023. This launch has dominated the news in the tech sector (and my social media feed) since its launch late last week, and for good reason. In many ways, this is one of the most anticipated product launches in history. Expectations were sky high: a nearly two-and-a-half-year gap since GPT-4 in a field where major leaps come on a nearly monthly cadence, and this being from the company that kicked off the era of LLMs (large language models). An additional rub, OpenAI is in the middle of a fundraising round at a $500 billion (yes, with a B) evaluation, making it among a handful of privately held companies with valuations closing in on a 1$ Trillion. So, how did it actually do?
With expectations sky high, there was almost no chance GPT-5 would please everyone, and sure enough, the rollout has been divisive. But here’s my take: it’s another major step on the march toward Artificial General Intelligence, and eventually, Artificial Super Intelligence. GPT-5 isn’t perfect, but it’s also more than “a bit smarter.” It’s a unified, routed system that can run in different modes of inference: fast for quick surface-level answers, and slow/deep for complex, multi-step reasoning. Importantly, it appears to decide when to switch between them, even if imperfectly. That architectural shift, combined with broad capability gains, fewer hallucinations, and a clear jump in coding performance, are where the real advances lie. So, is it a bona fide Frontier Model and the new touchstone? Probably, but with the rate of progress in the field, it will likely be leapfrogged within the next month. Let’s dive into the details and see if you agree.
First, if you enjoy these updates, consider subscribing and becoming a part of our growing community!
A Unified Model with Fast and Slow “Thinking”
The central innovation in GPT-5 is a whole new brain architecture. Instead of a single model handling everything, GPT-5 is a unified, routed system: it actually consists of multiple specialized models under the hood. A “smart and fast” sub-model zips through easy questions, while a heavier deep reasoning model tackles the hard stuff – and a real-time router decides which one to use on the fly. Ask a simple prompt, and you get an answer back in a flash; ask it to solve a novel math proof or complex engineering problem, and GPT-5 will silently hand off to its slow-but-steady thinker. In essence, GPT-5 can shift gears automatically, trading speed for brainpower when needed. OpenAI also rolled out Mini and Nano versions of GPT-5 – smaller models that handle overflow once you hit usage limits. The idea is to give users the best of both worlds, quick responses for trivial tasks and deliberate, step-by-step logic for more complex questions.
This routed design is clever, but it isn’t without glitches. Early adopters, myself included, noticed the system sometimes mis-routed prompts, handing a complex query to the “fast” brain when it really needed deep thought, resulting in shallow or generic answers. Essentially, GPT-5 would sometimes take the easy route when it shouldn’t. OpenAI rushed to patch the issue (it’s been dubbed “broken router” incident), and stability has improved. It’s a reminder that this architecture is brand-new tech; growing pains were inevitable. Despite the hiccups, the consensus is that GPT-5’s hybrid approach is a leap forward in efficiency. We’re likely to see future models from others adopt similar multi-model orchestration if this proves effective.
Smarter Scores: GPT-5 Dominates Benchmarks
Hype aside, how does GPT-5 actually perform? By the numbers, it’s setting new records on many AI benchmarks, though with some nuance worth unpacking.
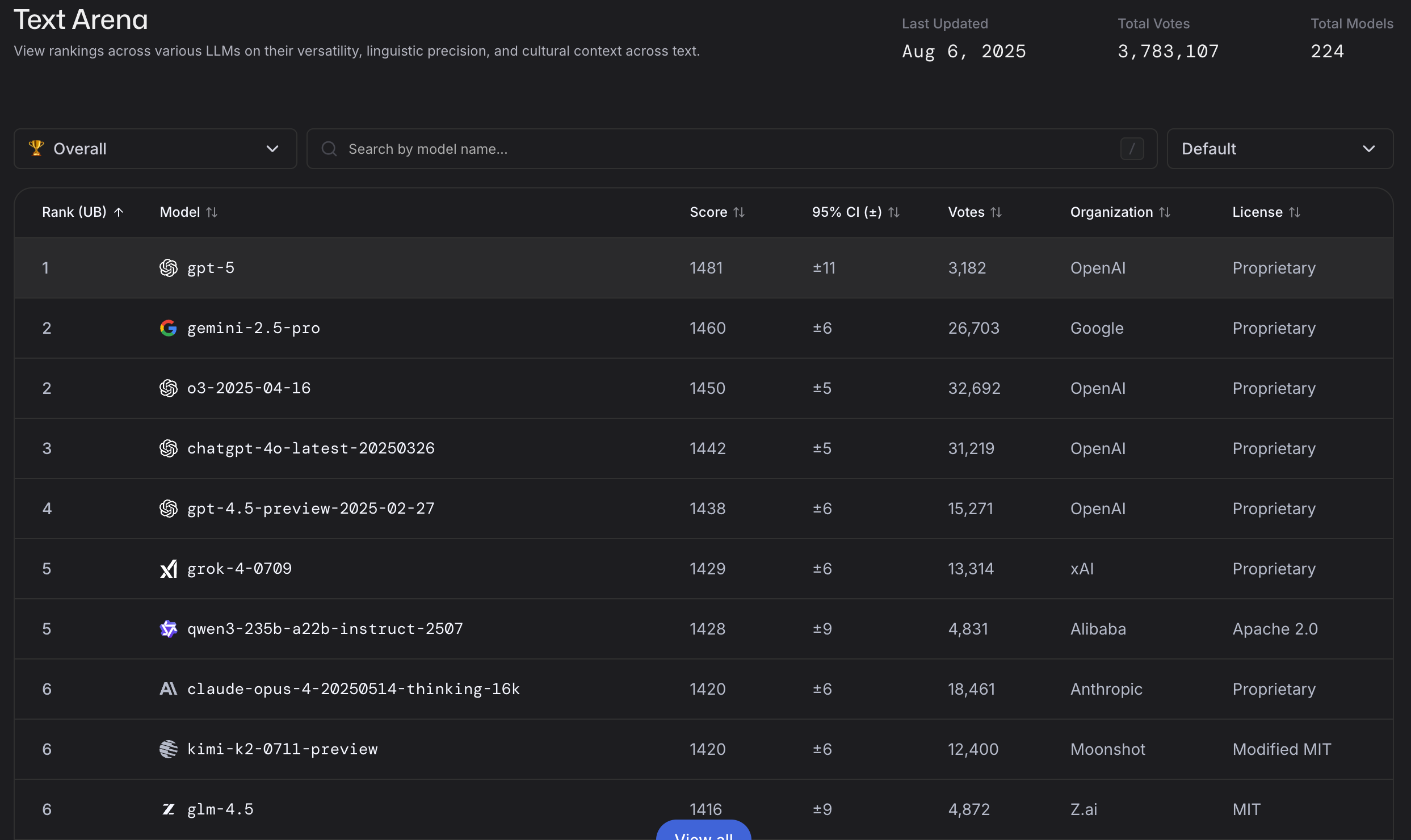
LM Arena – New #1: GPT-5 rocketed to the top of the LM Arena leaderboard, a popular crowdsourced ranking of large language models in head-to-head conversations. In fact, GPT-5 took 1st place in the main “text-based interaction” category, leapfrogging all competitors. It’s not just slight edge, either – in specialized tests (like coding challenges and web-based tasks), GPT-5’s lead in Elo score is even larger. For users, this means GPT-5 is currently the best model for quality interactive responses, out-chatting the likes of Anthropic’s Claude and Google’s latest Gemini (at least for now). One grumbling I’ve heard much of is that GPT-5 showed no “ontologically shocking” new tricks. But having a new LLM atop the leaderboards, is still strong progress. Perhaps we’re becoming spoiled.
ARC-AGI – Pushing the Cost-Performance Frontier: On the “ARC-AGI” eval (a sort of AGI-progress report that plots models’ scores against the compute cost to achieve them), GPT-5 has staked out a new Pareto frontier. In plain English, it’s getting the best results for the least computational cost seen to date. The secret is those scaled-down Mini and Nano GPT-5 variants. OpenAI has effectively achieved a big brain at small brain cost, and the smaller GPT-5s are hitting performance levels that used to require far larger (and pricier) models. One analyst called it a “hyper-deflation of the cost of intelligence”, an inflection point where cutting-edge AI is becoming dramatically cheaper to run. It also means we’ll see AI popping up in a lot more places, since the expense of using top-tier models is plummeting.
Frontier Math (Tier-4): Perhaps one of the most undersold results is that GPT-5 just set a new record on the Frontier Math Tier-4 challenge. This benchmark is like the Olympics of mathematical problem-solving, it includes problems so difficult that even professional mathematicians might spend weeks to solve one. They’re way beyond textbook exercises, yet they do have known solutions (so AI can be objectively scored). GPT-5’s performance has inched up the bar on these ultra-hard problems. Extrapolating the trend, experts estimate that by end of this year 15–20% of these “weeks-long” problems could be solvable by AI. Up until very recently, AIs could barely touch this category. In initial tests, GPT-5’s highest reasoning mode could crack a subset of Tier-4 problems that were totally out of reach before. It’s still far from human savant level (80%+ would be human expert territory), but the trajectory is clear. As one researcher put it, “a majority of extremely hard problems are now within reach, which was almost unimaginable a year ago.” I can imagine a world in the next couple of years where the field of math is basically “solved”.
HealthBench – Real-World Medicine: OpenAI also touted GPT-5’s prowess in the medical domain. They collaborated with 250 physicians to create HealthBench, a battery of real-world clinical tasks, and GPT-5 now scores higher on it than any prior model. In fact, GPT-5’s “thinking” mode achieved about 46% on the hardest medical scenarios, whereas even OpenAI’s last-gen model managed only ~32%. Those numbers might not sound high, but consider that doctors don’t always agree on tough cases, and a 100% score is essentially unattainable on such open-ended tasks. The takeaway is that GPT-5 is significantly closing the gap to expert physician performance. I think this is one of the areas we will come to have the greatest appreciation for our personal AI.
Humanity’s Last Exam (HLE) – On this 2,500-question “gauntlet” spanning advanced math, physics, law, philosophy, and linguistics, GPT-5 and its variants sit at the front of the pack alongside Grok. While OpenAI hasn’t published a single headline percentage for GPT-5, public leaderboard discussions and chart data show it trailing Grok slightly at the very top. For reference, Grok 4 without tools scored ~25–30% correct; in “Heavy” multi-agent + tool mode, it jumped to 44–51% . By comparison, Google’s Gemini 2.5 and other top models from Anthropic and earlier OpenAI releases scored several points lower in no-tool mode . GPT-5’s strong showing leans heavily on integrated search and other tools, highlighting that tool use and orchestration, not just raw model weights, are becoming decisive on these frontier AGI benchmarks .
700 Million Users and an AI Price Collapse
Beyond raw capability, GPT-5’s launch marks a watershed in scale and accessibility. Thanks to a year and a half of explosive growth, ChatGPT has an estimated 700 million weekly active users worldwide (roughly 1 in 10 people on Earth). Just last year, these frontier models were the province of tech enthusiasts; now we’re talking true mass adoption. And it’s not just individual tinkerers, OpenAI’s revenue has been soaring on the back of enterprise use. Around 5 million businesses are integrating ChatGPT into daily operations, from one-person startups to Fortune 500 companies. GPT-5’s release will likely amplify this trend, because OpenAI made a point to slash the costs for developers. The API pricing for GPT-5 undercuts previous models dramatically. For example, input tokens are about half the cost of GPT-4 (around $1.25 per million tokens for GPT-5’s full model), and the smaller variants are even cheaper. In fact, OpenAI priced GPT-5 roughly 40% lower than Anthropic’s flagship model (Claude “Sonnet”), again underscoring deflationary pressure in AI. It’s a strategy aimed towards ubiquity. By making GPT-5 affordable and fast, OpenAI is betting that AI becomes as commonplace in software as, say, search or cloud storage.
The implications for productivity are huge. When cutting-edge AI is available on tap for pennies, it democratizes who can build on it. A biotech student in a garage lab or a solo app developer can leverage GPT-5 with minimal costs, competing with far larger players. We’ve already seen a hint of this “cost collapse” effect in GPT-5’s mini and nano models essentially allow near-GPT-4 level performance at a tiny fraction of the compute. As one expert noted, intelligence is becoming too cheap to meter. Of course, tools alone don’t guarantee success, but history shows that when the price of a transformative technology drops, a wave of innovation follows. AI is likely no different. Expect an influx of AI-augmented tools in biotech, medicine, and engineering, basically every domain where knowledge or patterns recognition is key. We might look back on 2025 as the year AI started becoming a commonly expected tool like Google Search.
Although, it’s not all optimism. Quite the opposite, the launch of GPT-5 has come with lots of scrutiny. The AI community is polarized in its reaction to GPT-5. On one hand, there’s optimism: leaders in tech are urging companies to “go all in” on AI now that models are more reliable and robust. The vision is that GPT-5 and other frontier models will supercharge research and business, acting as co-pilots for nearly every knowledge task. On the other hand, there’s a lot of underwhelmed and dissapointed feedback.
Over-promised and under-delivered?
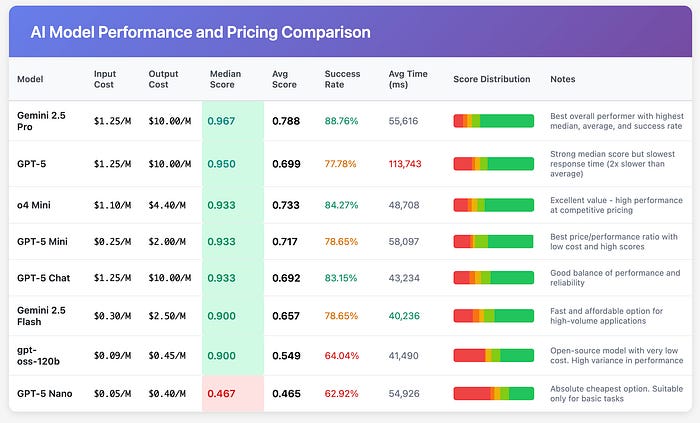
There’s a real counter-case being made by many super-users that GPT-5 is the emperor with no clothes. One post I found summarized many of their personal experiences along with other key indicators being on par or worse than past models. On a key task like SQL query generation, it couldn’t even beat a months-old rival. In the post linked above, the author ran their own benchmarks expecting GPT‑5 to crush it; instead Gemini 2.5 Pro outperformed GPT‑5 across the board while costing about the same. GPT‑5 was slower, pricier per query, and still didn’t do better – in fact, even OpenAI’s own earlier model (o3-mini) gave snappier, more efficient answers for basically the same accuracy.
I have no way to validate the benchmarks referenced above or in this post. I just want to make the point, there is a lot of controversy in the AI community regarding this launch. I truly do wonder how much any of these bench marks mean for good or bad.

There are some other real red flags too. Take 30 seconds and just look at this graph from the OpenAI presentation. Assuming you made at least a C in high school science, you can easily identify several glaring issues. For example:
GPT-5 without thinking achieved a score of a 52.8. The prior model o3 model and 4o were 69.1 and 30.8 respectively. Yet, GPT-5 is a much larger height than O3.
The height of the other bar graphs are not proportional, e.g., GPT-4o has the same height as o3 with their scores 2X different.
Finally, this is a nit, but there is no comparison between other flagship models such as Claude 4 Opus, Grok 3, or Gemini 2.5 Pro. Why?
These are glaring issues. You don’t need to have a PhD to spot these. If GPT-5 is supposedly as powerful as a PhD graduate, it should be able to notice this, right?
Another annoyance, OpenAI quietly killed off their older models the moment GPT‑5 launched. Without warning or transition, they yanked GPT‑4.5, O3, O4-Mini; all the previously available models vanished from ChatGPT overnight. People who relied on those for specific workflows were left high and dry.
The Bottom Line
Our expectations were never going to bet met with GPT-5 unless it was an out of the box super intelligence. Despite this, there are a lot of new and important features here, like the router + thinking duo makes the assistant feel intentional, not just verbose; the coding and health deltas look real; and distribution through Microsoft and GitHub means the gains show up where teams already live. If you’re running bio or engineering workflows, expect fewer papercuts and steadier end-to-end execution. It doesn’t feel like a Nobel Prize moment. But it’s meaningful progress.
These newsletters take significant effort to put together and are totally for the reader's benefit. If you find these explorations valuable, there are multiple ways to show your support:
Engage: Like or comment on posts to join the conversation.
Subscribe: Never miss an update by subscribing to the Substack.
Share: Help spread the word by sharing posts with friends directly or on social media.
References:
(https://medium.com/@austin-starks/i-tried-my-best-to-like-gpt-5-i-just-cant-it-fucking-sucks-7133a1dddfcb)
https://www.ainvest.com/news/openai-500-billion-valuation-secondary-share-sale-strategic-deep-dive-ai-frontier-2508/
https://medium.com/@adnanmasood/openais-gpt-5-is-here-a-deep-dive-into-the-system-card-for-ai-that-s-smarter-safer-and-faster-bca6effe5a8d#:~:text=,you%20need%20a%20market%E2%80%91wide%20view
https://epoch.ai/frontiermath?utm_source=chatgpt.com
Austin Starks: "PhD-level intelligence? Bitch please."
"Another annoyance, OpenAI quietly killed off their older models the moment GPT‑5 launched. Without warning or transition, they yanked GPT‑4.5, O3, O4-Mini; all the previously available models vanished from ChatGPT overnight. People who relied on those for specific workflows were left high and dry."
AI is starting to look like a test the way a wife-beating husband is a test: How much hatred and disrespect can a company show for its paying customers before the customers realize they're being abused and walk away?
Of particular interest to me would be from a medical or health prospective. In the article, it was mentioned that agreement between those evaluating medical situations differed and was debatable at times. Wondering what kind of results could be obtained using these same scenarios on different AI platforms, and an evaluation by AI of these comparative results (sort of a debate among the platforms).